2018-8-31 不小心把 <img src='base64'/>图片存进数据库的补救方法
抽出来变成图片文件,替换URL

文章里的代码高亮不好看。我扔到了 Github Gist:
可以去那边看。
https://gist.github.com/1c7/4ab1422d57dcb752917d6be1563fbc36
这篇文章讲什么
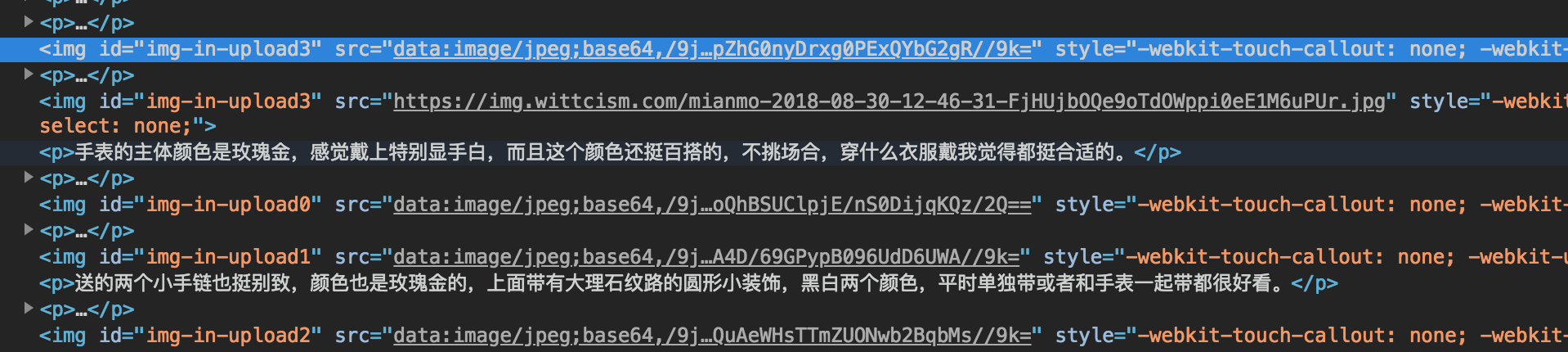
不小心把 base64 图片存进数据库里的补救方法(HTML 格式如下图)
<img src='data:image/jpeg;base64,......etc..very long' />
这篇文章对谁有用?有什么用?
对谁有用:后端程序员
有什么用:提供了代码。可以把 base64 抽出来变成图片文件然后上传
1. 出错原因(为什么会误存 base64 到数据库)
因为做了个网页编辑器(用了 Quill)
用户可以写文章。文章当然要允许用户插入图片。
希望的功能是:插入图片尽快在编辑器里显示。
技术实现是:先插入 base64 格式图片,等上传图片到七牛完成了。把 base64 换成七牛地址。
Javascript 插入 base64 示例代码如下:
var reader = new FileReader();
reader.onload = function(e) {
var base64Img = e.target.result;
// 插入编辑器
};
reader.readAsDataURL(file);
造成问题的地方:替换 base64->url 的 Javascript 代码有误。没能成功替换。
导致提交时把 base64 提交到数据库里了。
问题的表现形式:载入文章非常非常慢,因为 base64 拖慢了,整个网页有5M-20M大小
2. 解决思路
- 在数据库里找到出问题的是哪些文章(问题影响范围)
- 处理这些文章。把 base64 img 从数据库里抽出来。变成图片文件。手工上传到七牛。
- 替换文章内容,把 base64 换成上传到七牛之后的 url。保存回数据库里。
3. 步骤
- 找出问题文章。在数据库里按大小排序即可。
SQL 代码如下
select id, title, length(content_html), status from topics order by length(content_html) desc
因为这一步只是要看数据,找到出问题的文章 ID,所以工具无所谓。
我这里用的是 Mac 上的 Navicat Premium
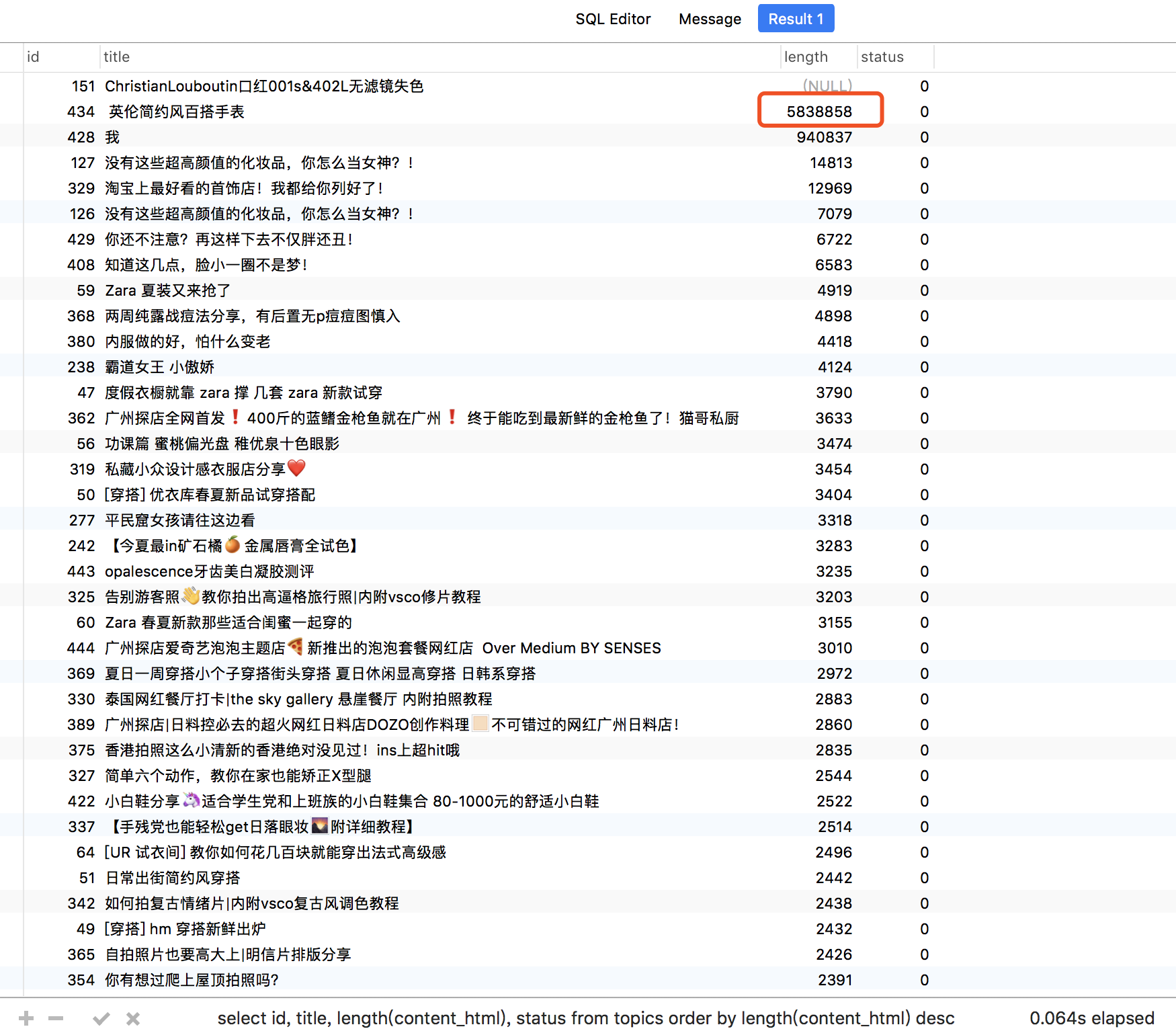
可以看到 id 434 的内容非常大。
- 把文章保存到本地
我直接在 Ruby on Rails 里写了个方法
def clean
id_array = [434]
id_array.each do |one|
filename = "./topic_id_#{one}.html"
t = Topic.unscoped.find(one)
open(filename, 'w') { |f| f << t.content_html}
end
render json: 'done'
return
end
代码解释:遍历 id,从数据库里找这个 id 的文章。
把 content_html 存到 topic_id_343.html 这个文件。
(文章内容是存在 content_html 这个字段里)
我是直接在 routes.rb 里写了条路由。访问就可以执行这段代码

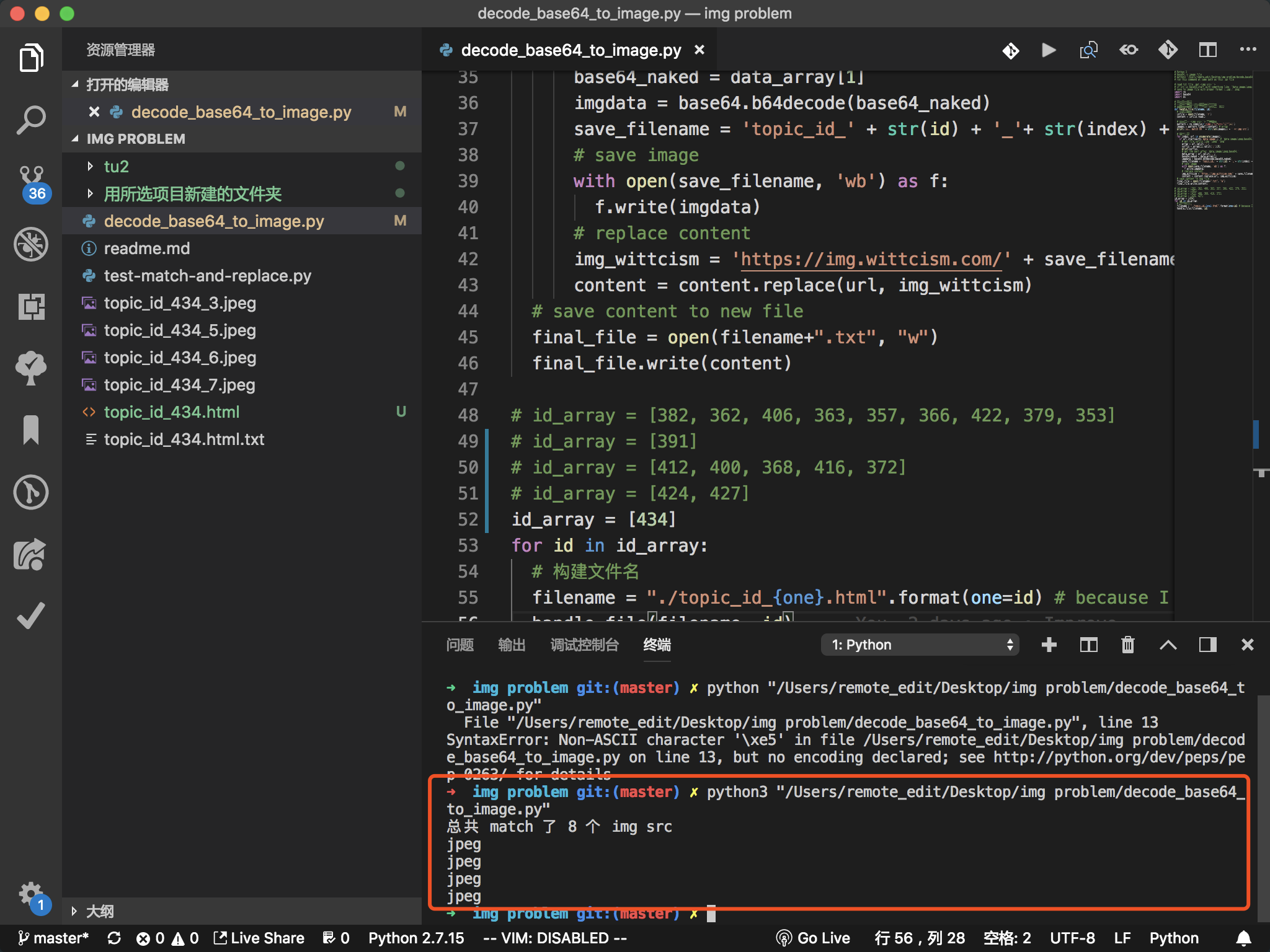
执行完获得一个 5.8M 的 .html 文件
- 现在文章内容数据在本地了,我们把 base64 抽出来变成图片文件
Python 代码如下
decode_base64_to_image.py
# Python 3
import re
import base64
import os
# 处理单个文件
# 图片会抽取出来,方便手工上传七牛
# 新内容会存在 .txt 里面,不会修改原文件
def handle_file(filename, id):
# 读文件内容
infile = open(filename, 'r')
content = infile.read()
# 正则拿到 <img src=''> 里的内容
pattern = re.compile(r'<img [^>]*src="([^"]+)')
images = pattern.findall(content) # array
print('总共 match 了 ' + str(len(images)) + ' 个 img src')
# 遍历图片
for index, url in enumerate(images):
if url.startswith('data:image'): # 'data:image/jpeg;base64,' 'data:image/png;base64,'
# get file suffix like "jpeg" "png"
array = url.split('/')
suffix = array[1].split(';')[0]
print(suffix)
# get the part after 'data:image/jpeg;base64,'
data_array = url.split(',')
base64_naked = data_array[1]
imgdata = base64.b64decode(base64_naked)
save_filename = 'topic_id_' + str(id) + '_'+ str(index) + '.' + suffix
# save image
with open(save_filename, 'wb') as f:
f.write(imgdata)
# replace content
img_wittcism = 'https://img.example.com/' + save_filename
content = content.replace(url, img_wittcism)
# save content to new file
final_file = open(filename+".txt", "w")
final_file.write(content)
id_array = [434]
for id in id_array:
# 构建文件名
filename = "./topic_id_{one}.html".format(one=id) # because I would place file like "topic_id_353.html" here
handle_file(filename, id)
这一段代码也比较短,简单说就是:
构建文件名(topic_id_343.html) 扔进 handle_file() 函数。
handle_file 函数做几件事:
<img src='base64'抽出来,变成 x.jpg 或者 x.png 图片- 复制 .html 里的内容,替换 base64 变成 URL。保存到 .html.txt 里
简单来讲,如果只看输入输出
输入:
- 和
.py在同一个文件夹下的.html文件
输出:
- xxx.jpg
- xxx.html.txt
原文件不会被修改
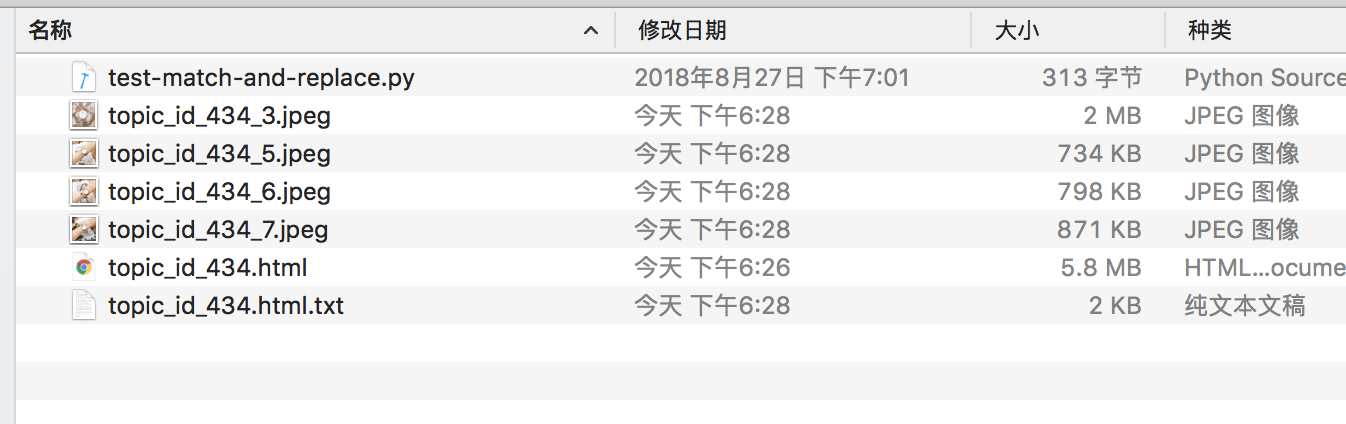
-
图片有了。下一步是手动上传到七牛。
(是的你可以做成全自动化。让 Python 上传到七牛,但是我没那个心情去写上传七牛的 Python 代码)
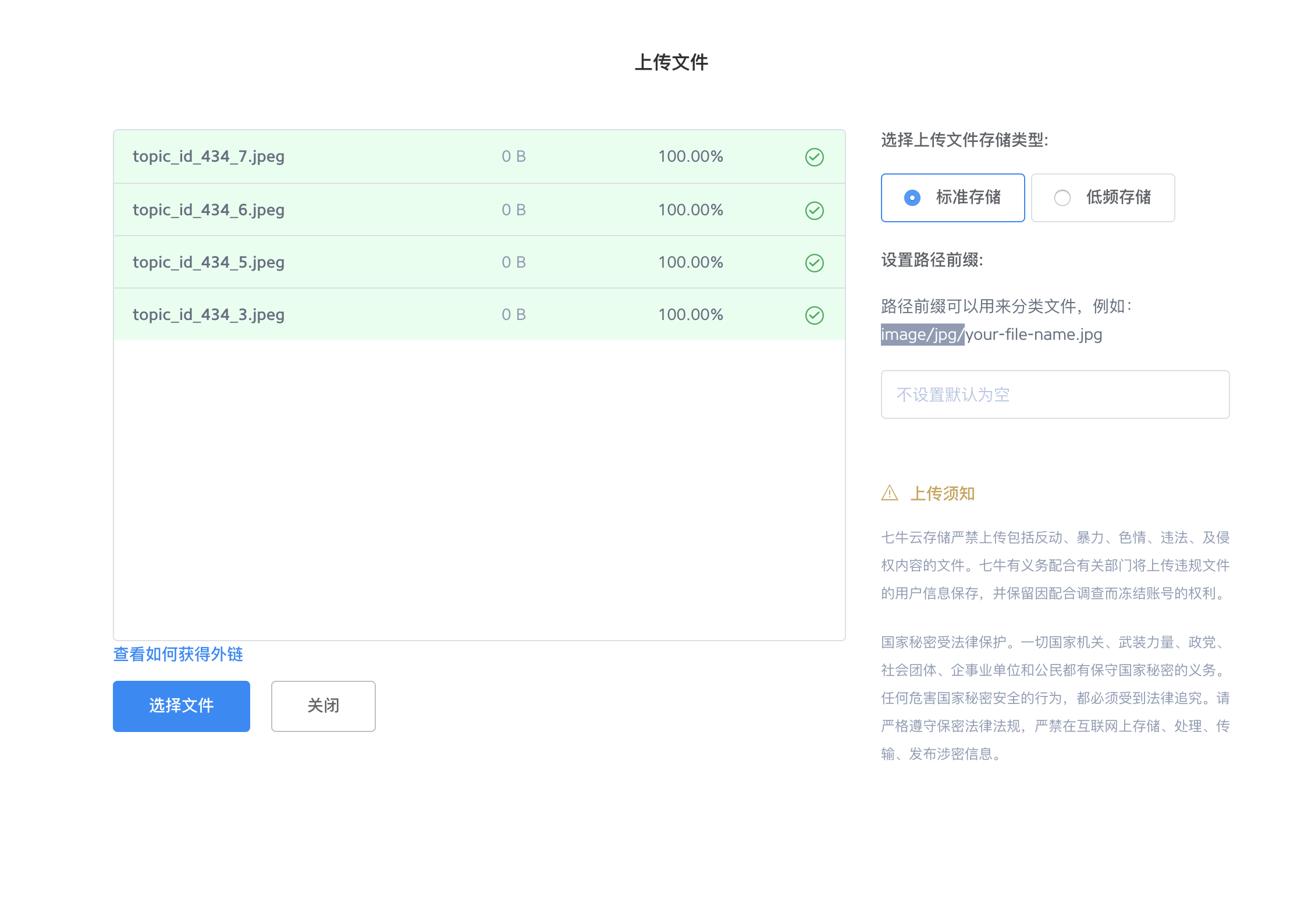
-
图片上传完了。那么更新数据库内容即可
复制 topic_id_434.html.txt 里的内容
然后写如下一段 Ruby on Rails 代码
id = '434'
content = '[内容填这里]'
t = Topic.unscoped.find(id)
t.content_html = content
t.deleted_at = nil
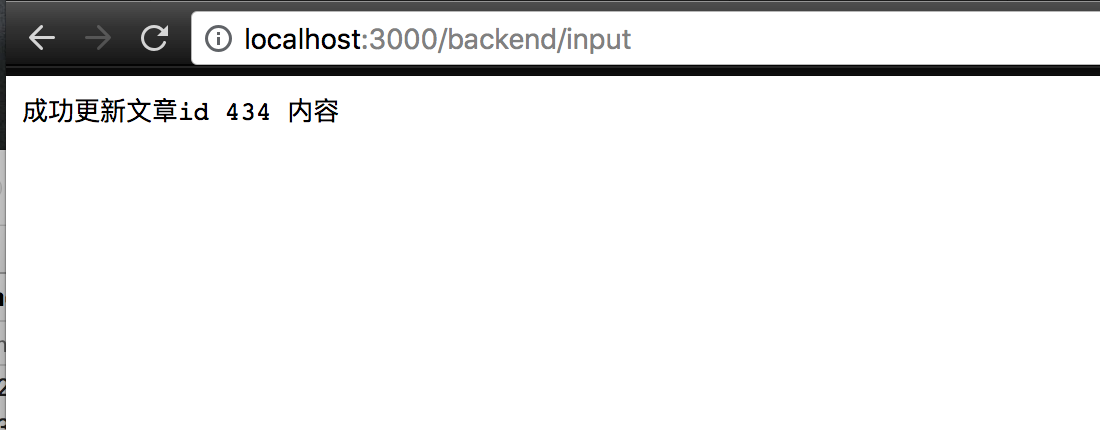
t.save
render json: "成功更新文章id #{id} 内容"
return
end
它做的事情是。把 content 插入到 id 为 434 的 content_html 字段中。
保存。
再检查一次
select id, title, length(content_html), status from topics order by length(content_html) desc
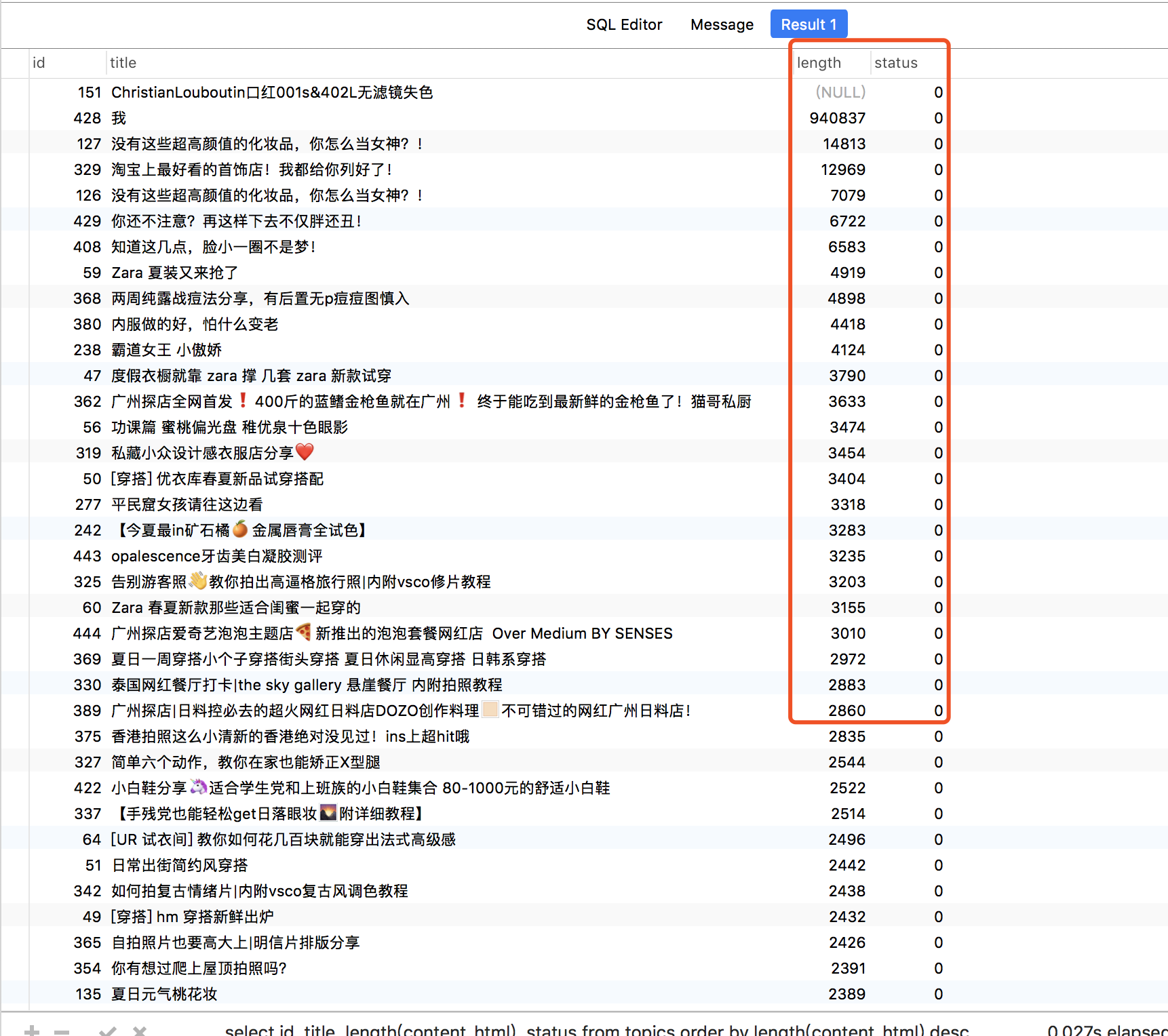
可以看到大小修复了。id 434 没有排在上面了。
另外注意:"我"这篇文章只是测试用的草稿。这篇的大小无所谓。
全文完
希望这篇文章对你有帮助