[教程] Ruby on Rails 上传文件到 AWS S3 并让用户可以下载
不看这篇文章查着谷歌自己做:耗时1-2小时,读这篇文章然后做:20分钟

![[教程] Ruby on Rails 上传文件到 AWS S3 并让用户可以下载](/content/images/size/w2000/2020/02/-.jpg)
这篇文章讲什么?
Ruby on Rails 怎么上传文件到 AWS S3,并且让用户可以下载文件
对谁有用?
Ruby on Rails 开发者
有什么用?
节省开发时间,文中有核心概念和代码可供参考
这篇文章有什么意义?
因为乍看起来,就一个上传下载而已,似乎没什么难的,有什么好写的?
答:对,的确没什么"难"的,只是耗时而已,我花了大概1-2个小时。
读者看完这篇文章,只需要花20分钟左右就可以解决问题
使用场景
功能描述:后台有一个"导出"功能。成品是下载下来一个 .csv 文件。
一开始的做法是直接返回文件,代码类似这样:
csv = [CSV.generate相关代码]
# csv 最后是个 csv 类型的 string
send_data csv, filename: "abc.csv"
问题是导出的记录越多,就越慢,而且可能失败。
对于时间久的任务,就让它后台做,做好了通知我们
成品演示
第一步:点击导出
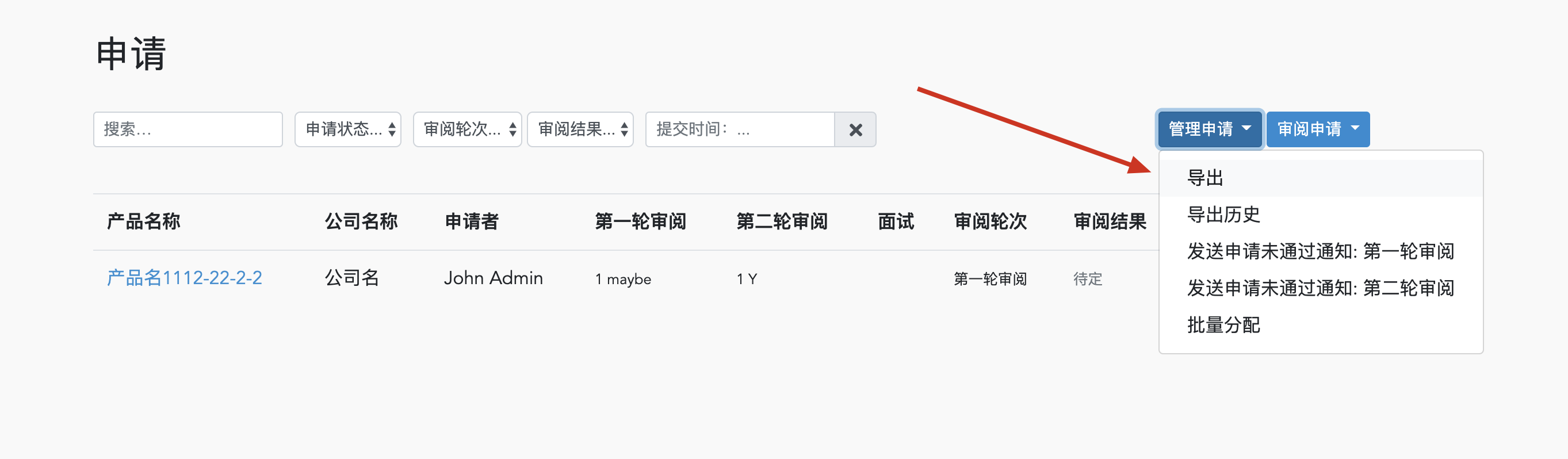
会看到顶部有绿色的文字提示
导出已开始, 请在 '管理申请'->'导出记录' 查看导出是否完成并下载结果
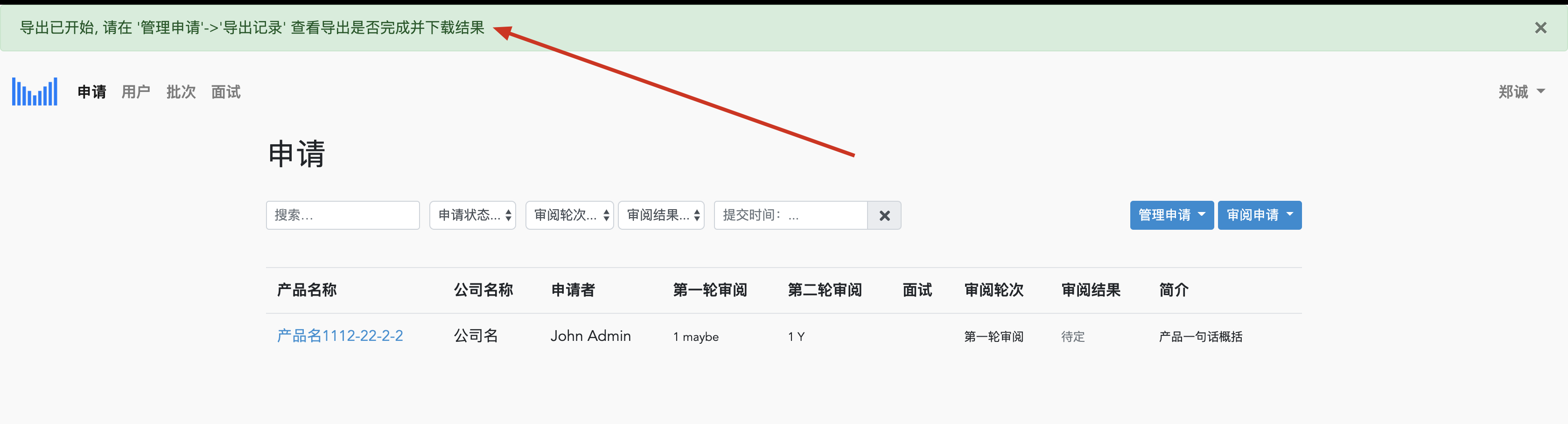
然后我们去导出记录里面看:
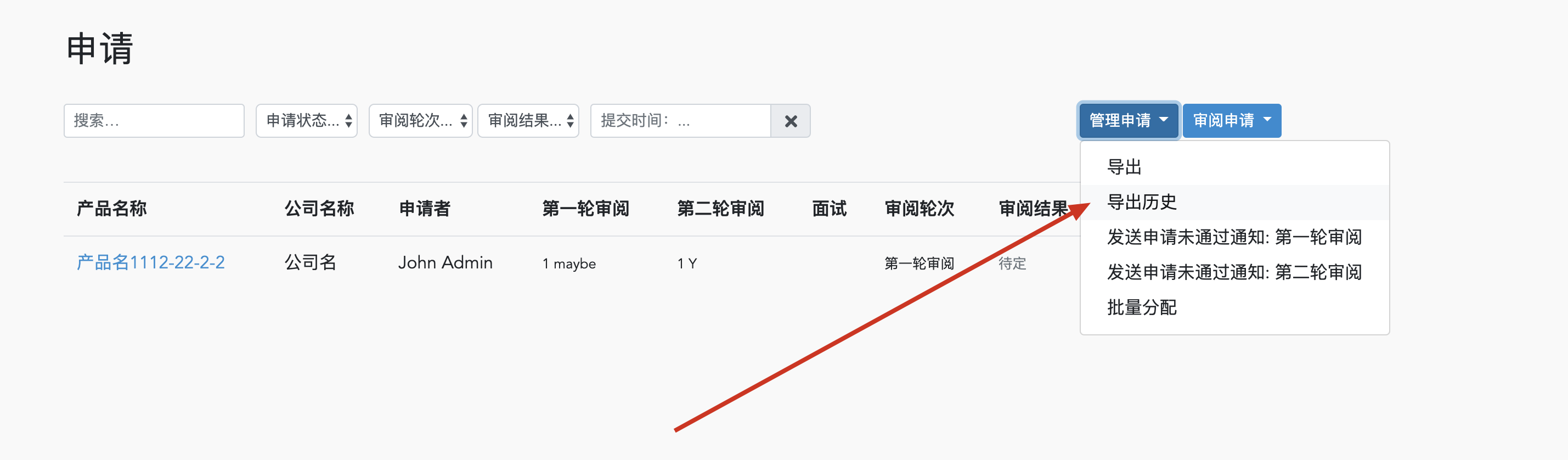
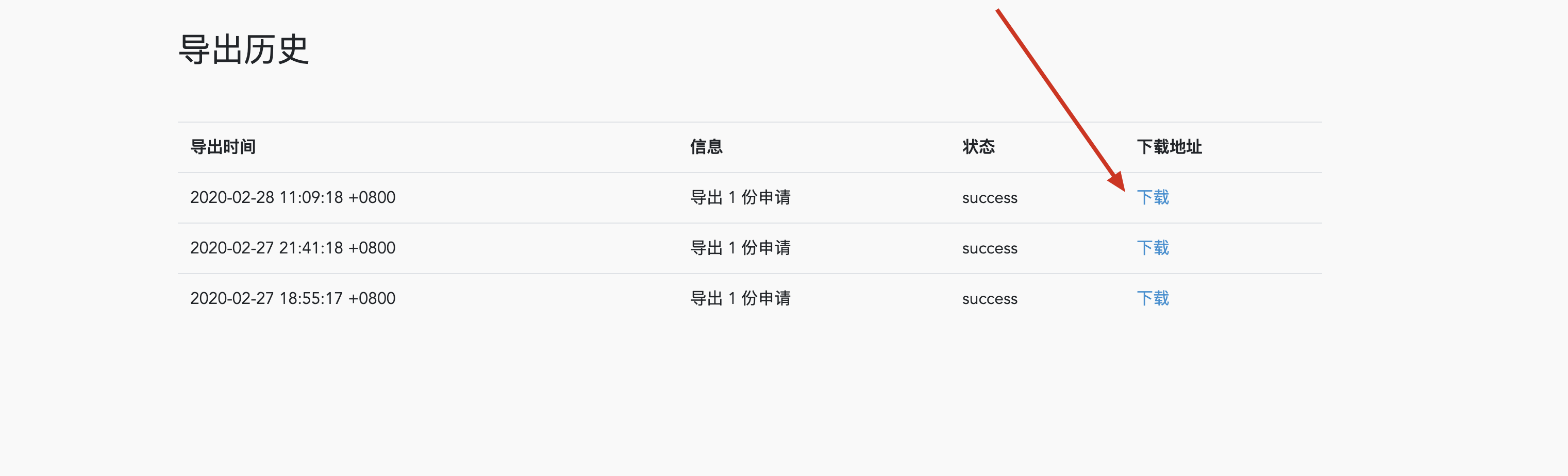
可以看到下载链接了
代码示例开始
第一步:上传文件到 S3
app/jobs/export_to_s3_demo.rb
我用 Que 做队列 (读者可能用 sidekiq 或其他)
我直接把整个 job 代码贴过来(同时删了一些无关代码并做了注释)
require 'aws-sdk-s3'
require 'date'
class ExportToS3Job < Que::Job
self.queue = '[队列名]'
def run(export_history_id)
csv = "[假设这里是 csv string 的内容]"
# 写入一个临时文件
temp_file = Tempfile.new('export_application_csv')
temp_file.write(csv)
# S3 桶的名字
bucket = '[S3 桶的名字]'
# 存入 S3 的文件名
proper_filename = "导出.csv"
# 上传到到 S3
Aws.config.update({
credentials: Aws::Credentials.new(ENV['AWS_S3_CREDENTIALS_KEY'], ENV['AWS_S3_CREDENTIALS_SECRET'])
})
s3 = Aws::S3::Resource.new(region: 'cn-north-1') # 指定地区
obj = s3.bucket(bucket).object(proper_filename)
obj.upload_file(temp_file) # 上传
# 上传完毕,我们把信息存下来
export_history = ExportHistory.find(export_history_id)
export_history.s3_filename = proper_filename
export_history.success!
destroy
end
end
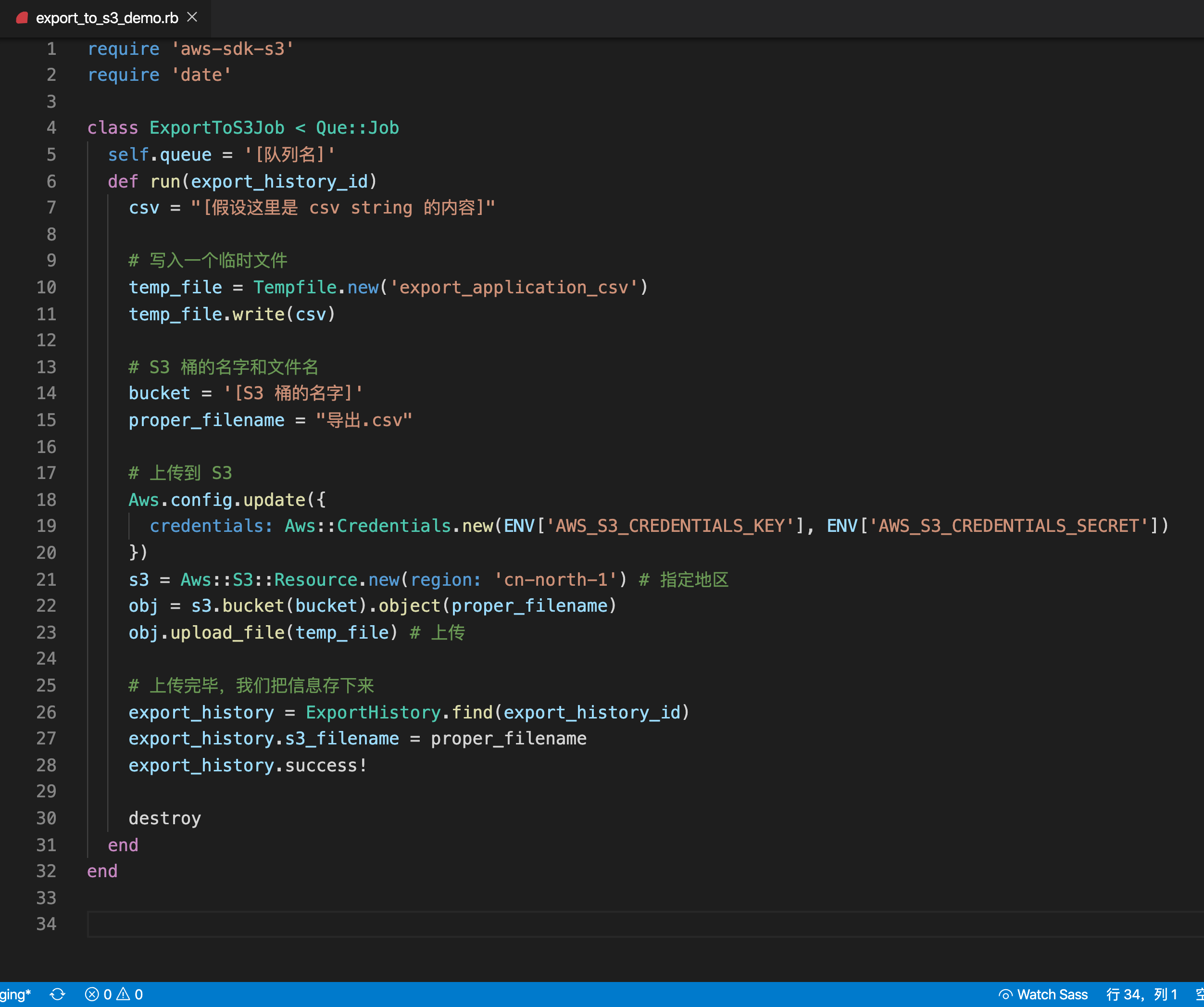
核心点:
- 使用了
gem 'aws-sdk-s3' Aws.config.update提供必要的机密信息- 最后
obj.upload_file上传
代码里最后一部分只是把文件名存下来而已
(第26行到28行,ExportHistory.find 那里)
注意这个文件名应该独特一些,
可以是(用户 id)+时间戳,不然 S3 bucket 里面同名文件覆盖会产生问题。
以下是 ExportHistory Model 的内容
# == Schema Information
#
# Table name: export_histories
#
# id :bigint not null, primary key
# deleted_at :datetime
# name :string
# s3_filename :string
# status :integer default("0")
# created_at :datetime not null
# updated_at :datetime not null
# user_id :integer
#
class ExportHistory < ApplicationRecord
enum status: {
exporting: 0,
success: 1
}
belongs_to :user
end
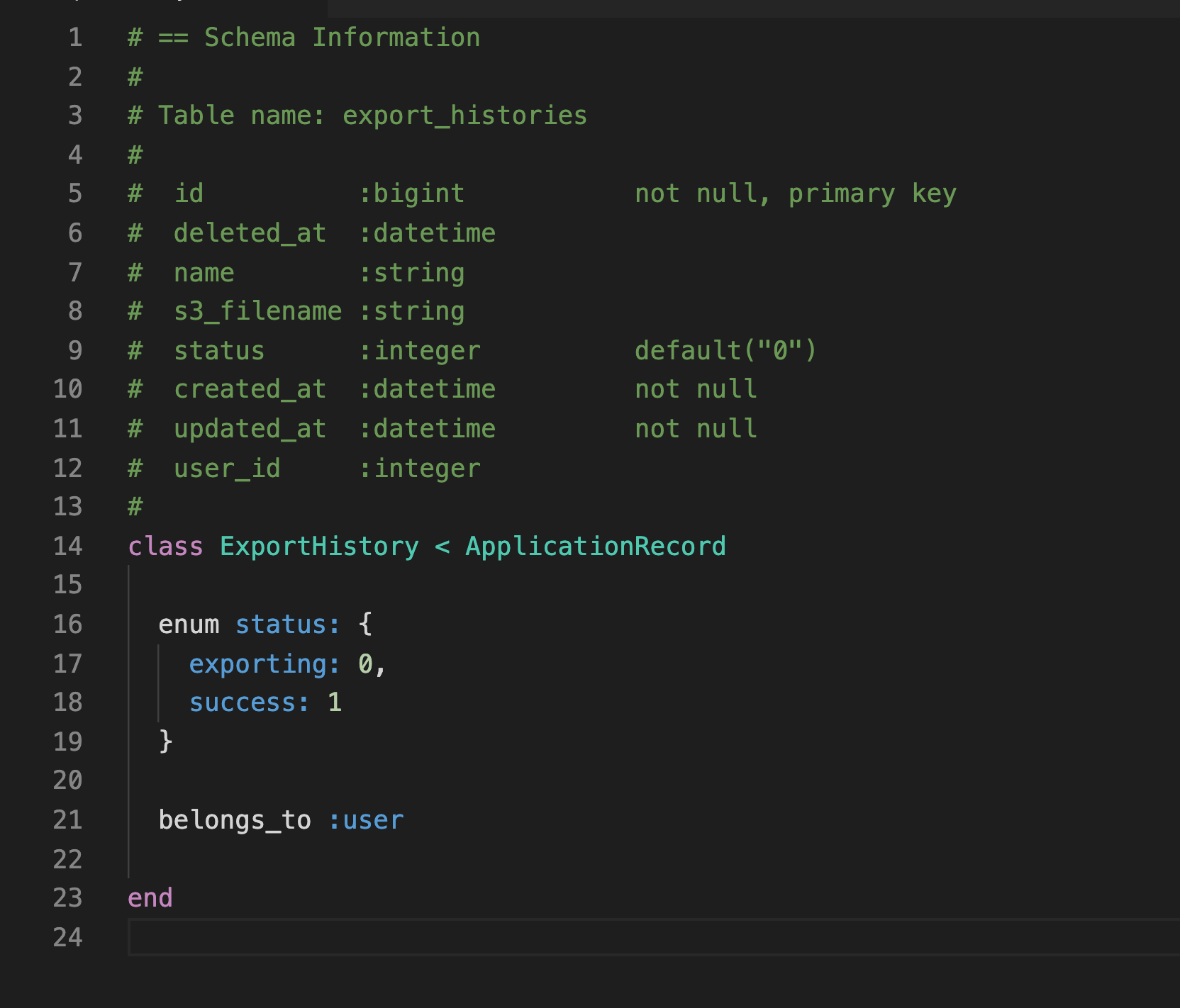
这个 Model 没啥特殊的,只是既然给代码就要给全,不能缺一块拼图。
第二步:既然上传完成了,我们来做下载
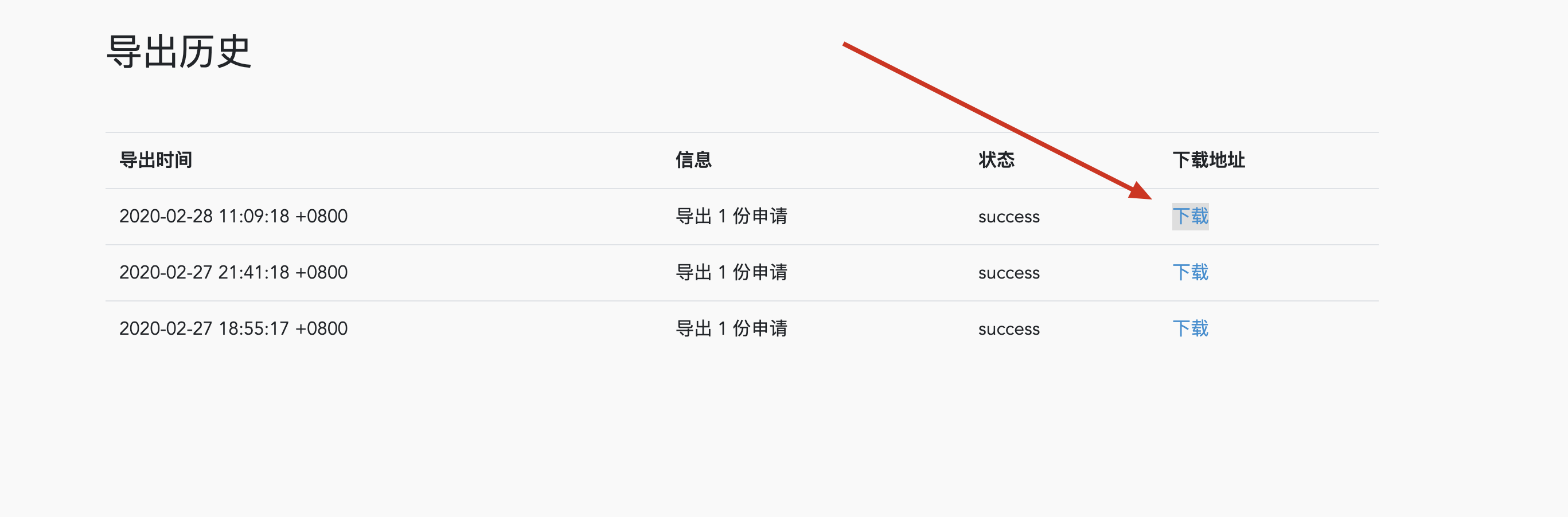
这个蓝色"下载"链接是指向我们的
http://localhost:3000/export_history/12/download
为什么不直接提供一个 S3 的下载链接?比如:
https://[桶的名字].s3.cn-north-1.amazonaws.com.cn/文件名.csv
理由:为了安全
如果把 bucket 做成 public access (所有人可访问)
可能会被人摸清楚 url 的规律,然后进行暴力破解。
我们希望文件只能是触发"导出"的用户自己下载,其他人都不能下载。
做法如下:
首先 view 我们是这样写的:
app/views/export_history/index.html.haml
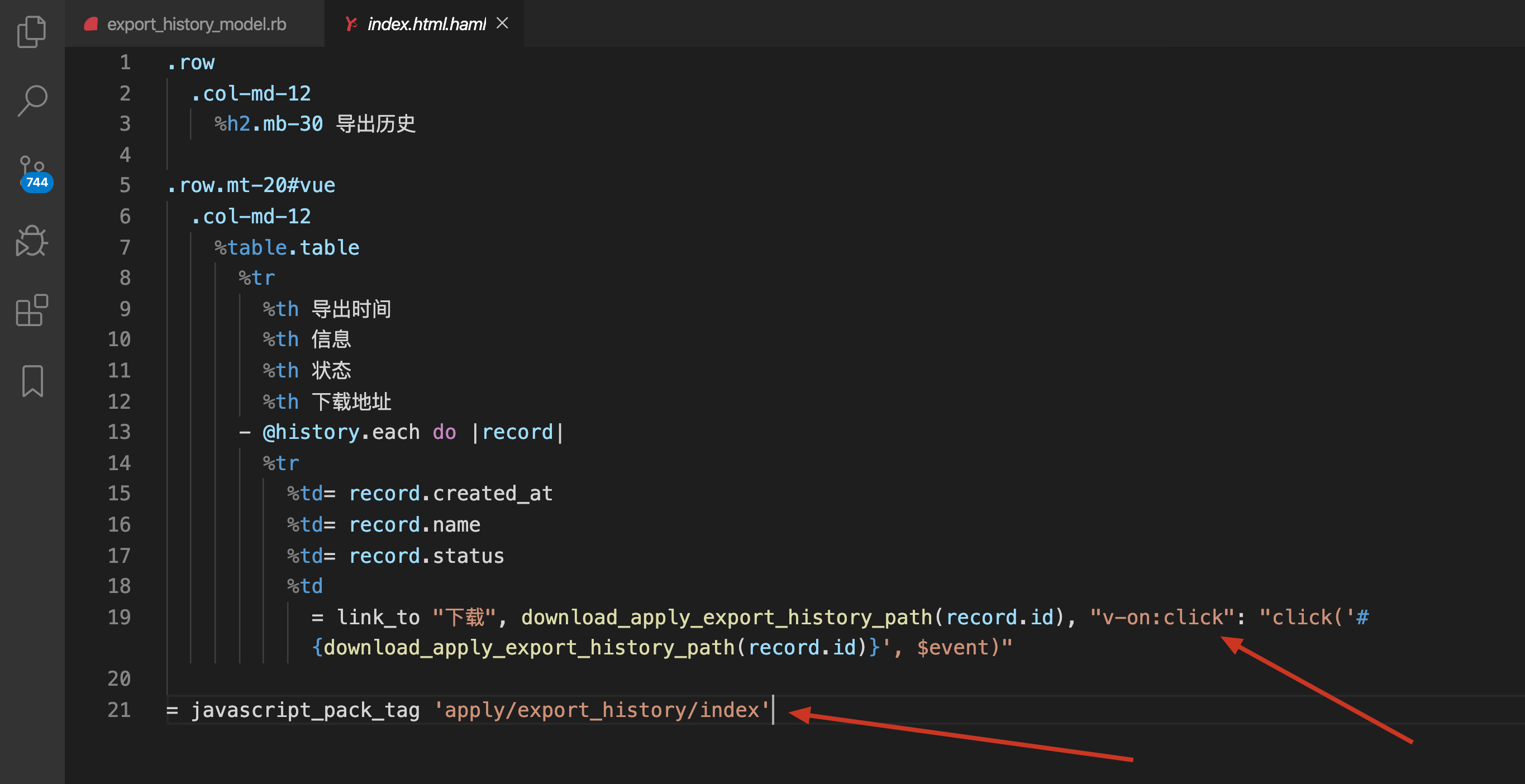
核心点:
- 用 Webpacker 的
javascript_pack_tag引入一个 js 文件。待会我们要用它来下载 - 这里用了 Vue.js,所以有 v-on:click,传进去的参数是
http://localhost:3000/export_history/12/download - 注意第5行的 #vue, 这是给 html 元素定了一个 id, 待会 Vue 挂载要用
我们来看看这个 js 文件
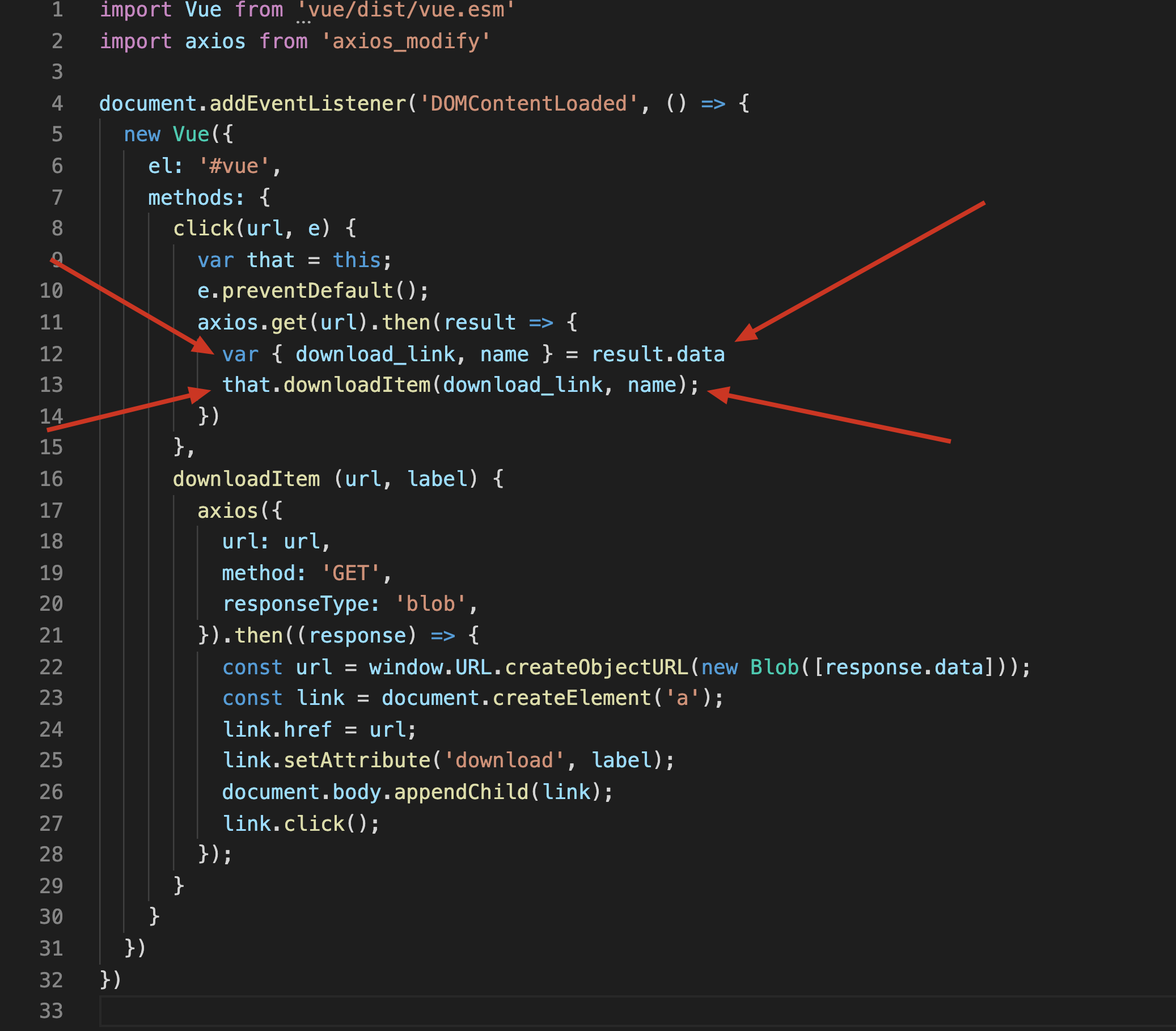
app/javascript/packs/apply/export_history/index.js
import Vue from 'vue/dist/vue.esm'
import axios from 'axios_modify'
document.addEventListener('DOMContentLoaded', () => {
new Vue({
el: '#vue',
methods: {
click(url, e) {
var that = this;
e.preventDefault();
axios.get(url).then(result => {
var { download_link, name } = result.data
that.downloadItem(download_link, name);
})
},
downloadItem (url, label) {
axios({
url: url,
method: 'GET',
responseType: 'blob',
}).then((response) => {
const url = window.URL.createObjectURL(new Blob([response.data]));
const link = document.createElement('a');
link.href = url;
link.setAttribute('download', label);
document.body.appendChild(link);
link.click();
});
}
}
})
})
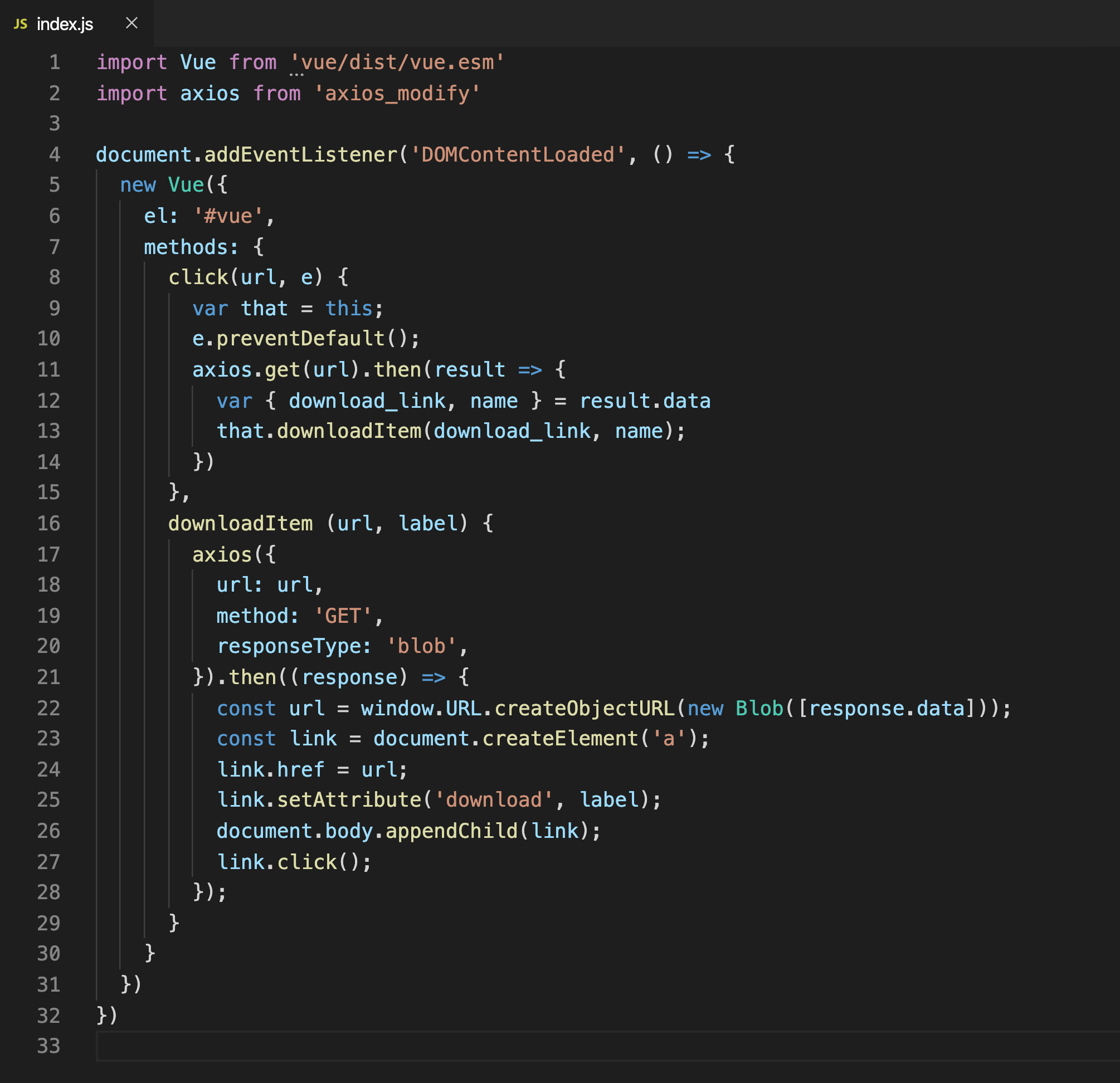
核心点:
- (第6行) el:'#vue' 挂载到一个 id 为 vue 的 html 元素上
- Vue 这里就 2 个函数,click 和 downloadItem
- (第8行) click 负责处理
<a>元素的点击事件(就是之前那个"下载"俩字) - (第11行) axios.get(url) 发请求到
http://localhost:3000/export_history/12/download - (第12行) 返回的数据里面有个 download_link
- (第13行) 我们再调用 downloadItem 去下载这个链接
再补充一个 .js 文件 axios_modify

app/javascript/packs/axios_modify.js
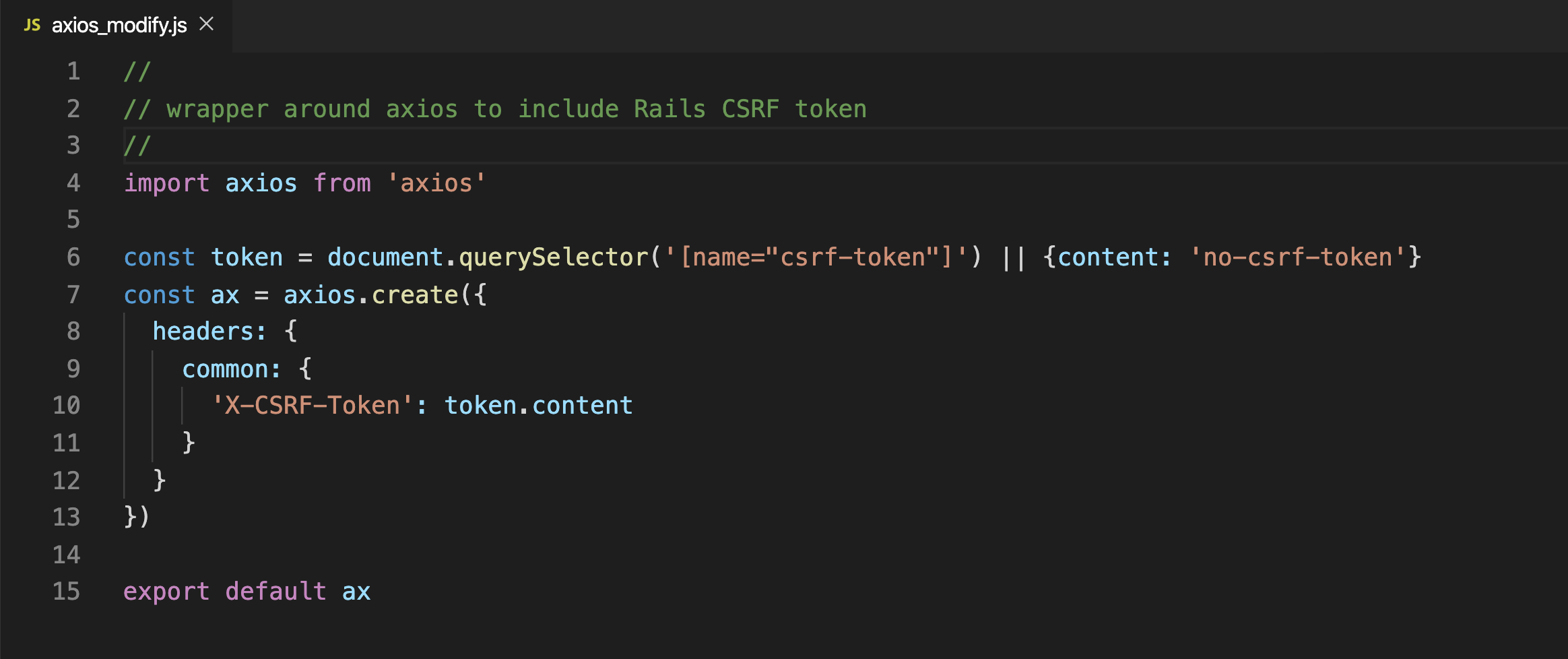
//
// wrapper around axios to include Rails CSRF token
//
import axios from 'axios'
const token = document.querySelector('[name="csrf-token"]') || {content: 'no-csrf-token'}
const ax = axios.create({
headers: {
common: {
'X-CSRF-Token': token.content
}
}
})
export default ax
这个 axios 只是把 CSRF token 带上而已
最后一步,我们来看看 controller
看看发了请求到 http://localhost:3000/export_history/12/download 之后到底发生什么
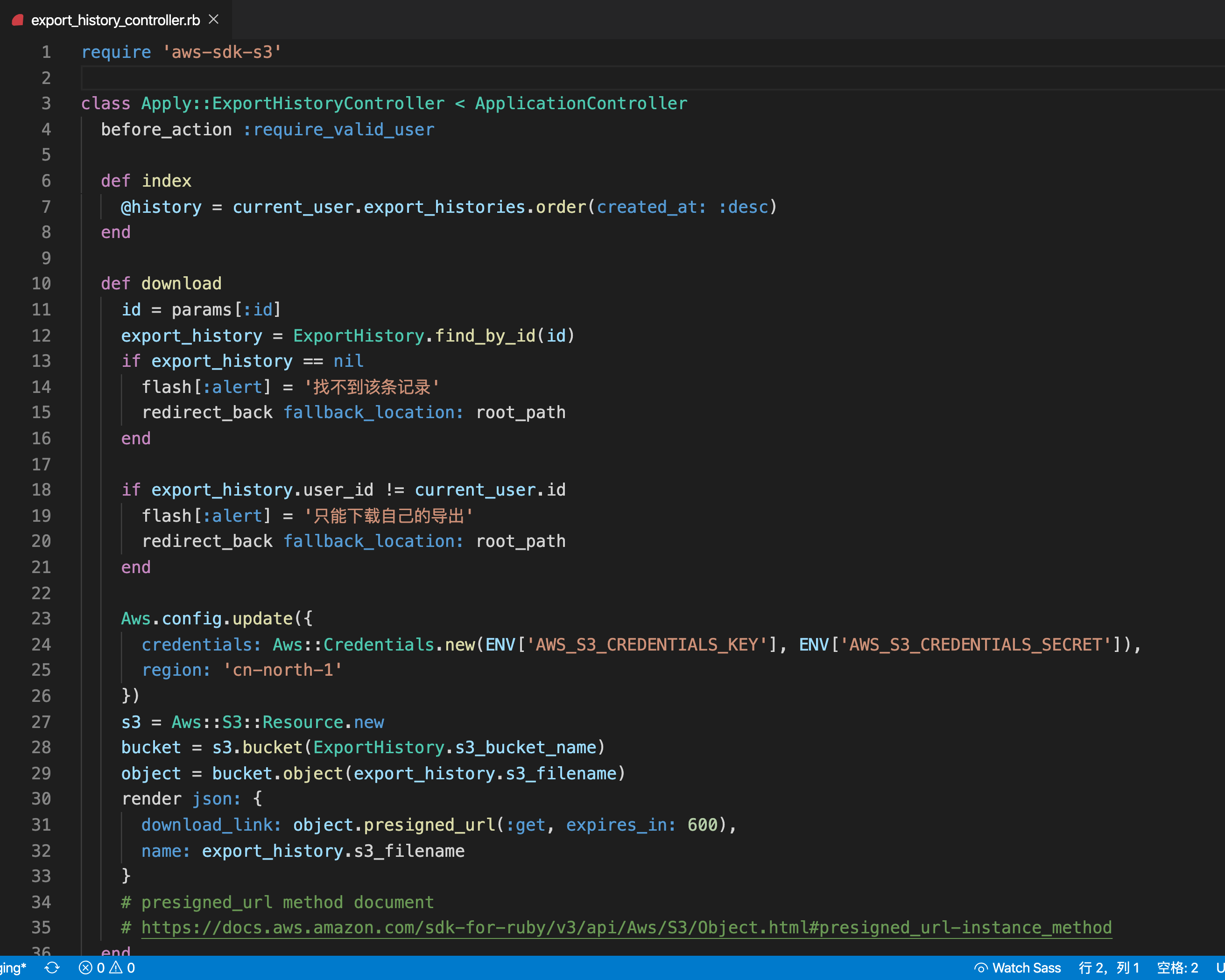
核心点
- def download 是核心,我们只看这个函数
第一部分
export_history = ExportHistory.find_by_id(id)
if export_history == nil
flash[:alert] = '找不到该条记录'
redirect_back fallback_location: root_path
end
if export_history.user_id != current_user.id
flash[:alert] = '只能下载自己的导出'
redirect_back fallback_location: root_path
end
只是基本检查而已,检查有没有这条记录 + 有没有权限
第二部分
Aws.config.update({
credentials: Aws::Credentials.new(ENV['AWS_S3_CREDENTIALS_KEY'], ENV['AWS_S3_CREDENTIALS_SECRET']),
region: 'cn-north-1'
})
是正确设置 AWS 的身份
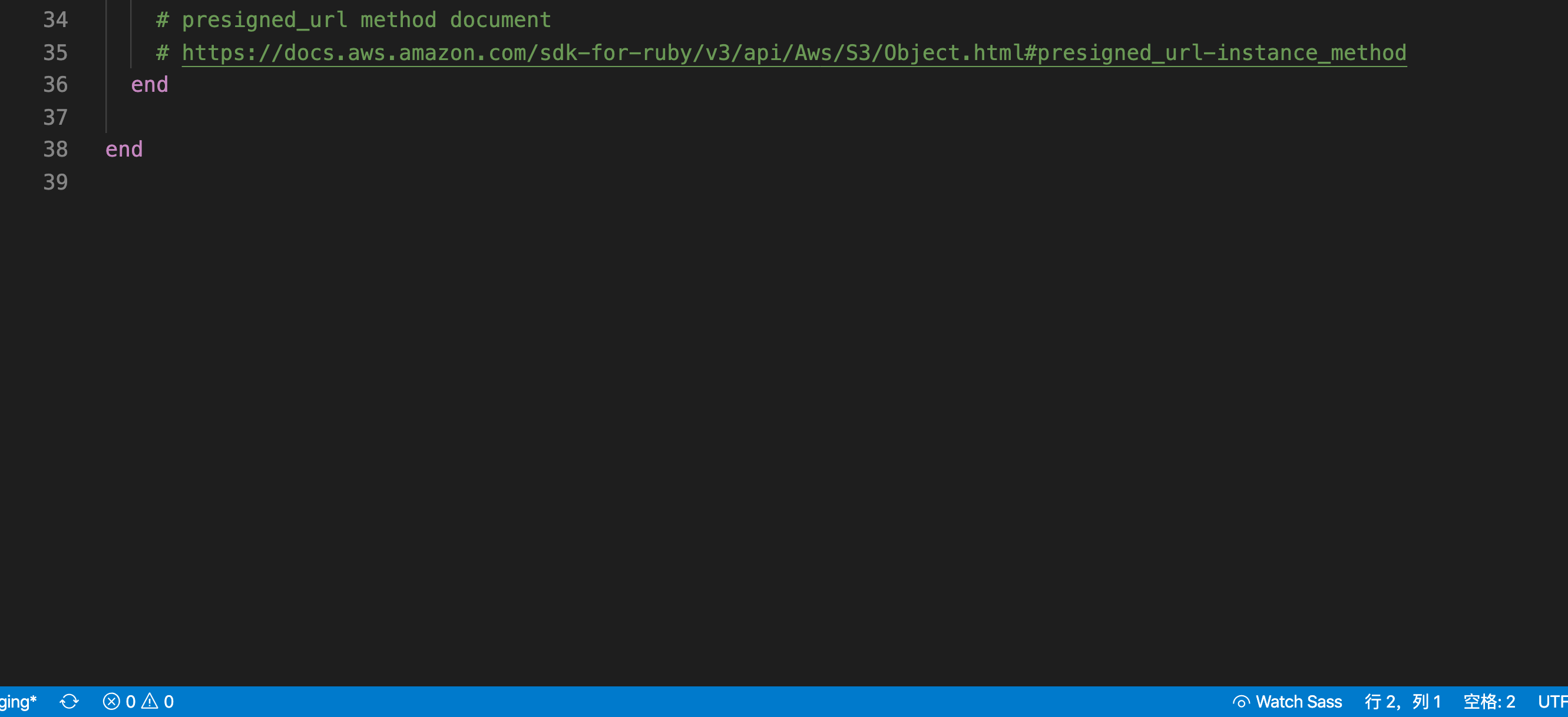
第三个部分(最后)
s3 = Aws::S3::Resource.new
bucket = s3.bucket(ExportHistory.s3_bucket_name)
object = bucket.object(export_history.s3_filename)
render json: {
download_link: object.presigned_url(:get, expires_in: 600),
name: export_history.s3_filename
}
# presigned_url method document
# https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Object.html#presigned_url-instance_method
核心是 object.presigned_url
意思是临时生成一个链接,有效期 600 秒(10分钟)
这里返回
{
download_link: x,
name:y
}
然后 js 来做下载
代码讲解完毕
全部核心点:
- 一个 job 负责上传文件,传完了把文件名存入数据库
- 一个 .html.haml 显示界面 (导出记录)
- 一个 .js 负责下载
- 一个 controller.rb 和 s3 交互,产生 presigned_url
presigned_url 文档
全文完
感谢阅读