Docker Swarm 教程-第3部分: 初次部署
写于2019-2-11。第3部分做完,终于看到 Rails 的 hello world 页面了。


第3部分接着 第2部分
第2部分做了什么
- 新建了1台 Azure 云主机
- 在 Azure 云主机上安装了 Docker,打开了端口 3000
- 在 Azure Container Registry 开了一个仓库。用于存储镜像
- 用 Google Cloud Shell 打包了个镜像 (docker build 命令)
- 用 Google Cloud Shell 把镜像推到了 Azure (docker push 命令)
长话短说就是:把镜像推到了 Azure。
第3部分的目标
用 Swarm 跑起来!
第1步:修改 docker-stack.yml,把镜像填进去
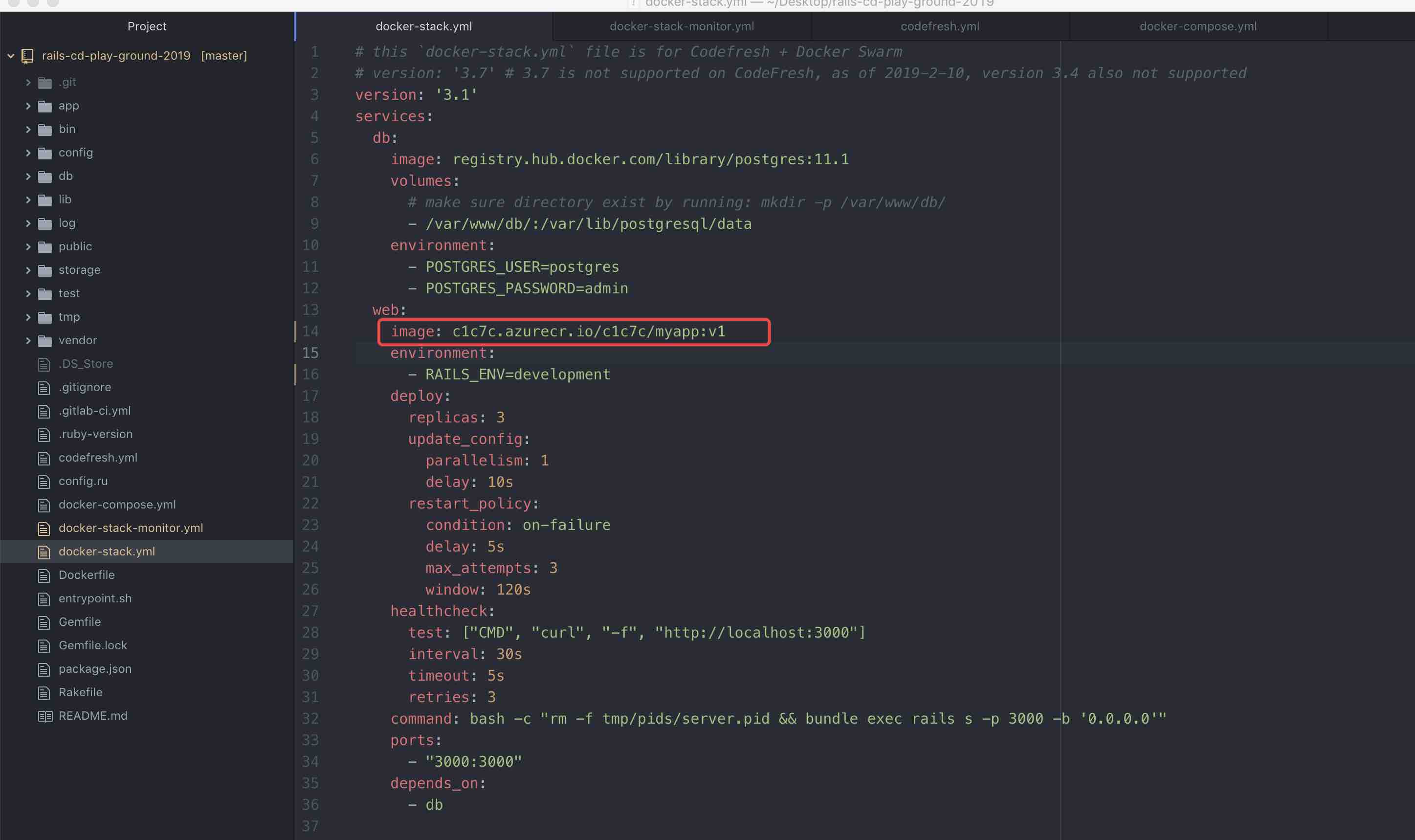
修改 image: c1c7c.azurecr.io/c1c7c/myapp:v1 这里就行,注意填你自己的镜像。
第2步:ssh 登录到 Azure 服务器
ssh [email protected]
第3步:git clone 把代码拉下来
sudo mkdir -p /var/www/docker-swarm-tutorial
sudo git clone --branch part1-to-3 https://github.com/1c7/docker-swarm-tutorial.git docker-swarm-tutorial /var/www/docker-swarm-tutorial
注意复制的是 part1-to-3 这个分支,理由在第2部分的教程说过了,这里不重复了。
第4步:切换成 root 用户并且进入代码目录
su -l
cd /var/www/docker-swarm-tutorial
第5步:新建需要的目录
mkdir -p /var/www/db/
新建这个目录是因为:
根据 docker-stack.yml 里的配置 PostgreSQL 会把数据存在这里。
实际开发中,database.yml 可以填环境变量。
指向比如 Amazon RDS,
或者 UCloud 提供的 PostgreSQL/MySQL 数据库服务。
或者你自建了一个允许远程连接的 PostgreSQL 数据库,然后填那个地址。
重点是:因为这里只是简单演示,所以数据就随便存在本地了。
实际生产环境中不能这样用。
第6步:登录 Azure 的 Container Registry,不然镜像拉不下来
比如我这里运行的是:
docker login c1c7c.azurecr.io
username: c1c7c
password: [填你自己的]
第7步:运行 docker swarm
docker stack deploy --compose-file docker-stack.yml --with-registry-auth app-2019

第8步:看运行成功没有
docker service ls

说明:我对 part1-to-3 分支进行了修改,以上这个图片里。REPLICAS 应该都是 1/1。而不是 3/3。
第9步:验证是否可以访问
curl localhost:3000
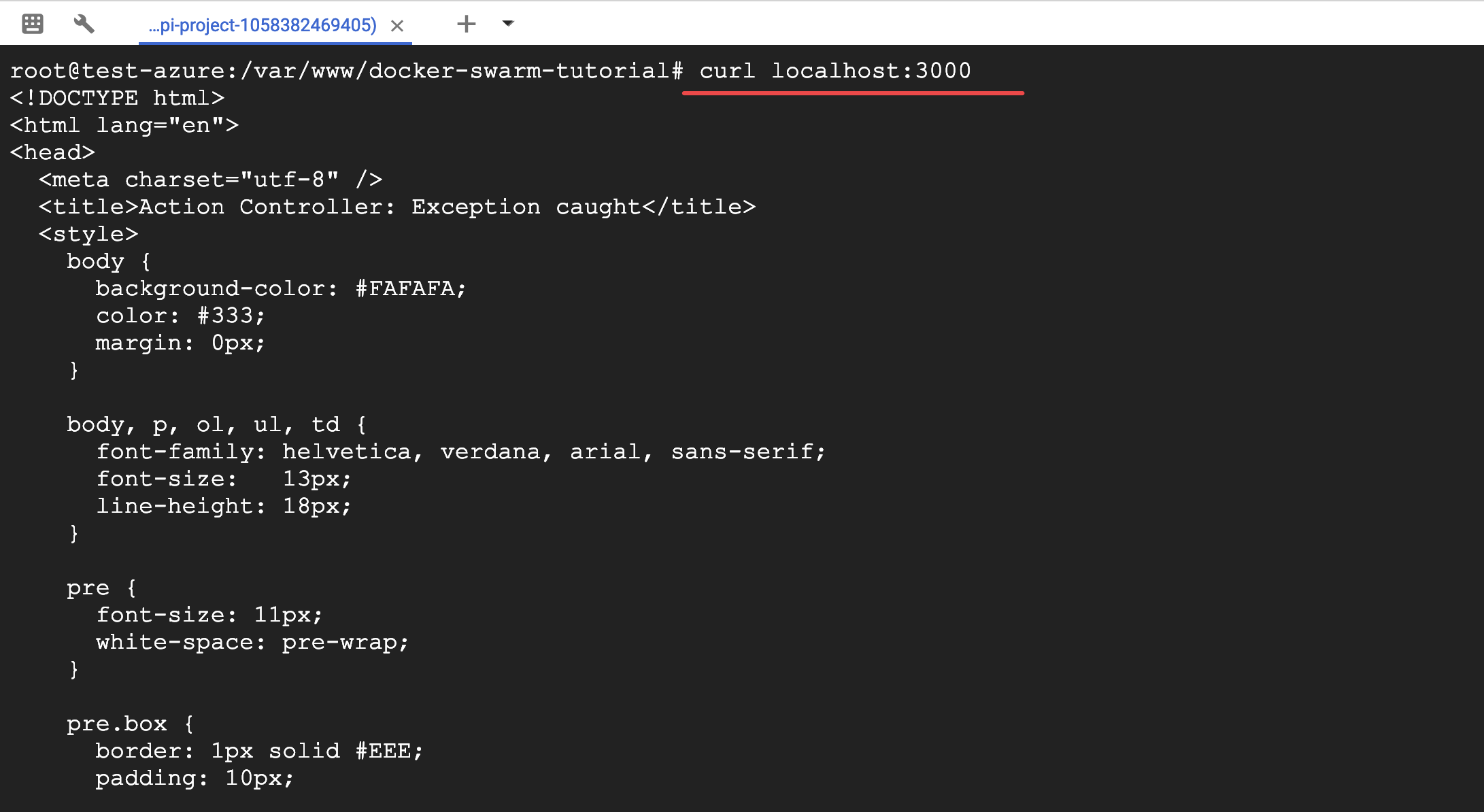
可以看到的确返回了 html,网站可以访问
第8步:访问网站
访问 40.121.23.32:3000
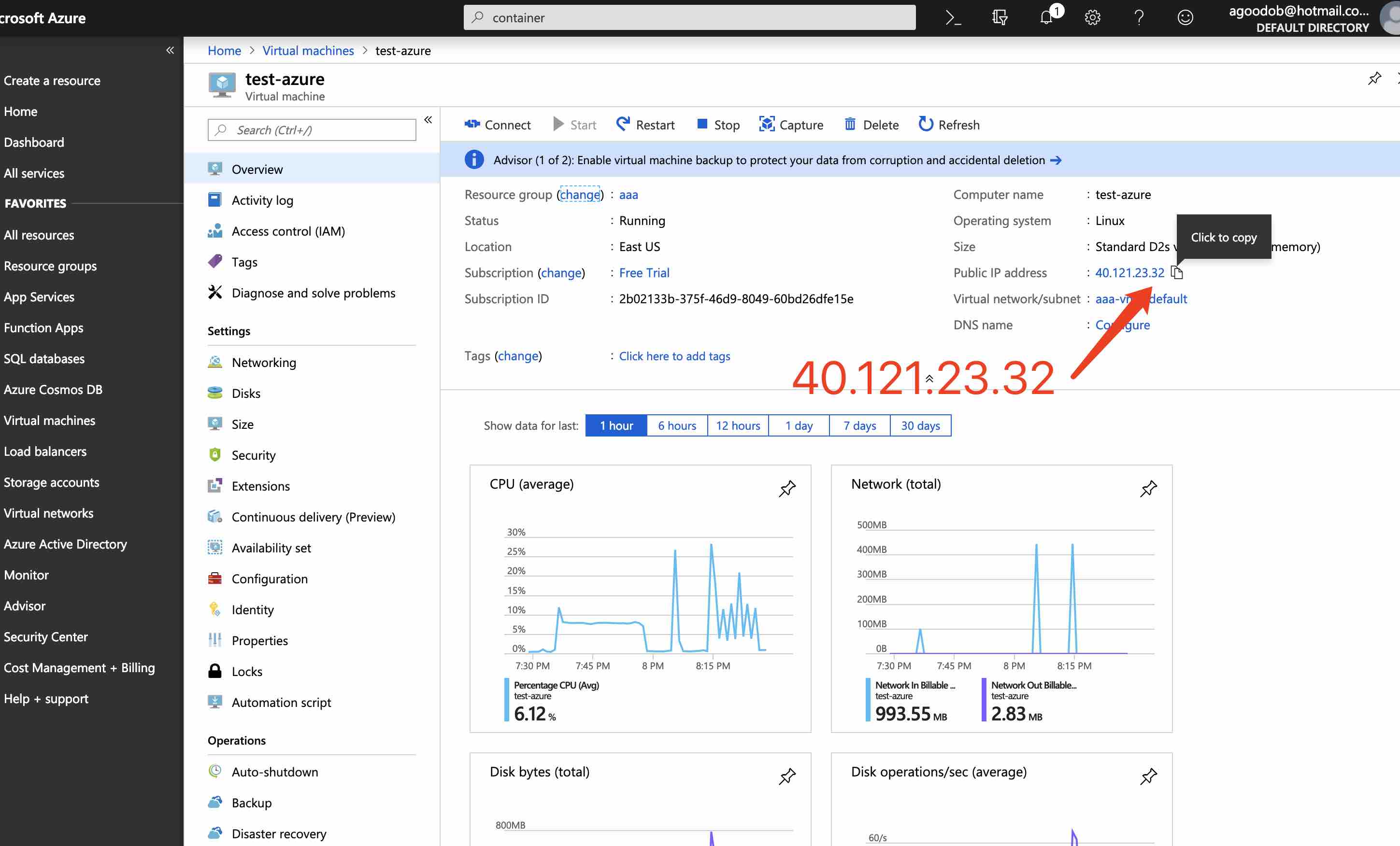
因为机器的 ip 地址就是这个。
你需要访问你的机器 ip 和端口。
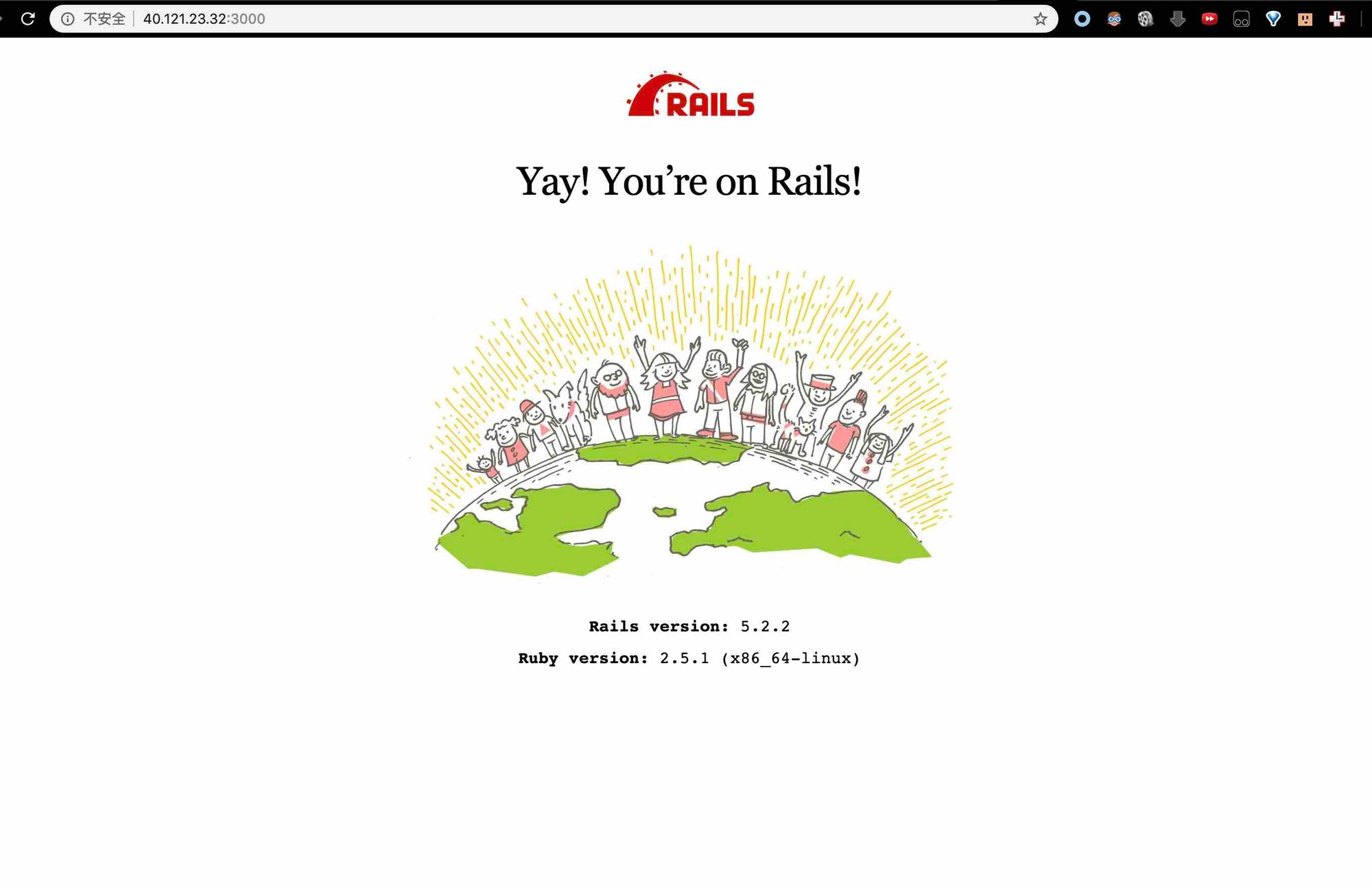
终于成功了!
总结下到底做了什么
- 打包镜像
- 推送镜像
- 用镜像部署 Swarm
虽然啰啰嗦嗦写到现在写了3个部分,但实质上做的就是几个简单的步骤。
需要手动在新机器上装 PostgreSQL 吗?没有!
装 Ruby?没有。
装 Rails?没有。
装 bundle 和 gem? 没有。
assest pipeline 编译?没有。
一台新机器 git clone 下来然后跑 docker stack deploy 就跑起来了。多方便。
告别每次有新机器就需要装这个装那个。。
第3部分结束。
接下来我们可以做什么?
到现在我们仅仅是看到 rails hello world 页面而已。
后面还有很多可以做的。日志,监控。0 downtime 更新(blue/green deployment)。
数据库还要弄对 (database.yml), secret 和 config 也还没学。
我们用的环境还是 RAILS_ENV=development
而且我们监听的是3000端口,实际用户肯定会访问80端口。
等等等等
展开讲讲更新代码要怎么做:
- 本地开发,写代码写到满意。
- 打包一个新镜像,比如用 v2 作为 tag (之前是 v1)
- 修改 docker-stack.yml,把 v2 镜像填进去
- 去服务器上再运行一次 docker-stack deploy
我知道这个步骤还是相对麻烦(还是有手工操作在里面)
这个部分是可以通过 CI/CD 工具做成完全自动化的。
只是我们的教程才刚刚开始,还没讲到那里呢。
展开讲讲 0 downtime 更新要怎么做:
之前完全没用 docker 时,
为了更新代码期间 Ruby on Rails 后端不能挂掉,我试过2个方案:
1. puma 的 phased_restart
这个方案的缺点是它不是 language agnostic。
意思就是如果我换成 passenger 或者 unicorn,这个方案就完全废掉了。
而且实际使用过程中我碰到过一个奇怪的问题,
在机器A上面 phased_restart 完美工作(大概10-20秒内就可以了)
但是在机器B上面 phased_restart 非常糟糕。启动很慢而且占用CPU高(更新一次要3-5分钟甚至更久)
我想尽么办法去 debug 解决问题,就是无法解决。
我去 Github 提 issue。
去 ruby-china 提问。都解决不了问题。这个方案最终在浪费掉我好几天时间后,只能放弃。
2. nginx 的 load balance
我是在网上搜的时候学会这个方法的。我也是 nginx 新手。
upstream app_witt {
server 127.0.0.1:9292;
# server 127.0.0.1:9696;
}
就是开2份 rails,然后指向其中一个。每次要更新了就更新另一个。
这个方法需要很多手工操作。非常闹心。
总之:有了 docker 和 docker swarm 之后,0 downtime deployment 就再也不是问题了。
而且是 language agnostic 的。哪怕我不用 Ruby on Rails 了。我用 PHP, Python, Java, Nodejs 任何语言都可以。